
Navigating Pharma Logistics: Trends, Challenges, and Solutions for 2025
The pharma market trends impact logistics with a shift to smaller, higher-value shipments and new temperature requirements.


When Frank Rosenblatt introduced a Perceptron in 1958, it was meant to be a machine for image classification that was connected to a 20×20 pixels camera. In today’s terms, a Perceptron is just a basic algorithm that can be used for linear classification problems in Machine Learning. Binary classification means we want to predict if our input falls into one of two classes. In the example below, these two classes are 0 or 1. Another examples could be diagnosing skin cancer from images, determine if an e-mail is spam, or detection of fraudulent payment.
The four basic components of a perceptron are inputs, weights, bias and an activation function.
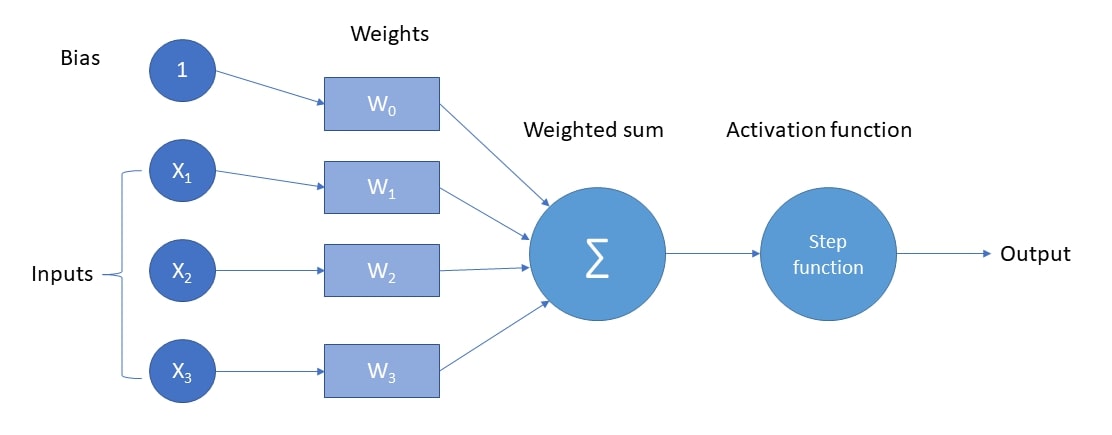
In figure 1 you can see how a perceptron works mathematically. The input gets multiplied by the weights and then summed up until we have a single number. Theoretically, right now we have an algorithm that does regression, but since we want to use it for classification tasks,we use a so-called activation function or step function.
Let’s look at a practical example: We want to know if a master data record has all required fields filled or not. Since we only care about if the fields are filled or not, we encode this information into three binary numbers. Hence, the input we will feed into our perceptron looks like this:
<field 1 is filled>, <field 2 is filled>, <field 3 is filled>
Also for this example, let’s assume the weights for our three fields are random numbers with the values <0.2, 0.4, 0.7>. Our activation function in this case will just be a simple rounding function. If the number is greater or equal to 0.5, it will take the value 1, which means all the required fields are filled, and else it is 0, meaning that not all required fields are filled. Let’s assume our input is <1,1,0>, which means only two of the three required fields are filled. We start by multiplying our first input “1” with our first weight “0.2” and we get 0.2 as a result. If we do this for all three pairs, we receive the vector <0.2, 0.4, 0>. Now the sum of all these numbers is 0.2+0.4 = 0.6 as an intermediate result for our perceptron.
Remember that so far, we have a real number which could be useful for a regression task, but since we want to have a “yes” or “no” at the end, we apply our activation function. If we round up 0.6, we get 1 and therefore our perceptron tells us that all the required fields are filled, which is actually not the case. So what went wrong? Well, nothing really, the result was just wrong due to randomly chosen weights in the beginning.
Here comes the fun part – training! We now need to find a way to adjust the weights in a way that given our inputs, this perceptron outputs a 0 instead of a 1. Let’s do another round, but this time we set the weights to <0.2, 0.25, 0.7>. If we multiply the pairs and sum them up, we end up with
0.2*1+0.25*1+0*0.7=0.45
which is rounded down to 0 after applying our activation function. And now we can see the output is the excepted one, which means our perceptron improved. Of course, this was a very easy example since you could find the perfect weights just by looking at the numbers and finger counting. In reality, neural networks have thousands of neurons each with weights attached and possibly different activation functions, making it it impossible to just create a perfect classifier by just looking at the numbers.
The pharma market trends impact logistics with a shift to smaller, higher-value shipments and new temperature requirements.

This blog post explores the role of remanufacturing and outlines how it can be successfully integrated into Product Lifecycle Management.

No-Code technologies allow businesses to adapt their transport management strategies swiftly and flexibly without complex programming.

In this blog post, you will learn the important difference between CX software solutions and customer experience as a business orientation.
