
Navigating Pharma Logistics: Trends, Challenges, and Solutions for 2025
The pharma market trends impact logistics with a shift to smaller, higher-value shipments and new temperature requirements.


Anyhow, researchers always had a profound interest in copying, imitating, and therefore claiming understanding of our brains and ourselves. An important step towards a field yet to be determined as Artificial Intelligence was made by McCulloch and Pitts, who created what can be understood as the first artificial neuron in the early 1940s: the threshold logic unit (TLU). It was designed specifically to model the mesh of neurons we have in our brains. We have already learned that neurons perceive electric input signals from the ones that connect to their dendrites. What happens (next) inside the neuron is some sort of activation: Neurons do not fire all the time, and they do not always send a signal to their neighboring neurons via their axons. This sort of activation – when a neuron fires versus when it does not – highly depends on the input. One rule of thumb became famous in that regard: “Neurons that fire together, wire together”. The degree of activation (“firing”) or conversely the degree of inhibition (“not firing”) is related to the input that neurons receive from other neurons that connect to it. That notion strongly resembles what happens in a circuit: on or off, zero or one, energy flowing or not.
If we interpret the communication between neurons in such a manner, we can think about implementing simple logic already: A neuron that fires means “true”, a neuron that rests means “false”. If we want to conceptualize this idea some more, how do we reach logical “true” and “false” with multiple inputs though? In simpler terms, how do we get to “firing” or “not firing” when a neuron receives signals from a handful of previous neurons, and from others they just get silence?
The researchers converted the neurons they modeled as inhibitors of a threshold function. What that means is that each neuron must contain a threshold value to fire: Say this threshold is 1, then in order to make the neuron fire, the sum of its inputs must reach 1. Otherwise, it shall remain silent. By combining and defining thresholds as well as signal strengths, we can model logic.
For example, say we have a threshold of 2 and two inputs that have a value of 1: In this case the two inputs summed together reach the threshold and the neuron shall fire. That corresponds to the logic AND. If we were to define the threshold as 1 and kept the inputs the same, we’d have an OR, because any of the inputs from previous neurons is enough to trigger the activation. In a nutshell: Any neuron receives an input signal from the previous neurons it is connected to. These inputs are added together, and the produced sum goes through an activation function as its argument. By that, we can simulate similar logic to electric circuits, because the way electrical signals are propagated in circuits is somewhat similar to how our nerve cells’ synapses work – on a very abstract level.
Remember the heuristic that neurons that fire together also wire together? The more often neurons fire together, the stronger their connection becomes. We simulate this connection by modifying the output of a certain neuron with a weight, depending on the downstream neuron it communicates with – and how often they have communicated in the past. Logically, the more communication has taken place, the higher the weight. This gives us a schematic for an artificial neuron:
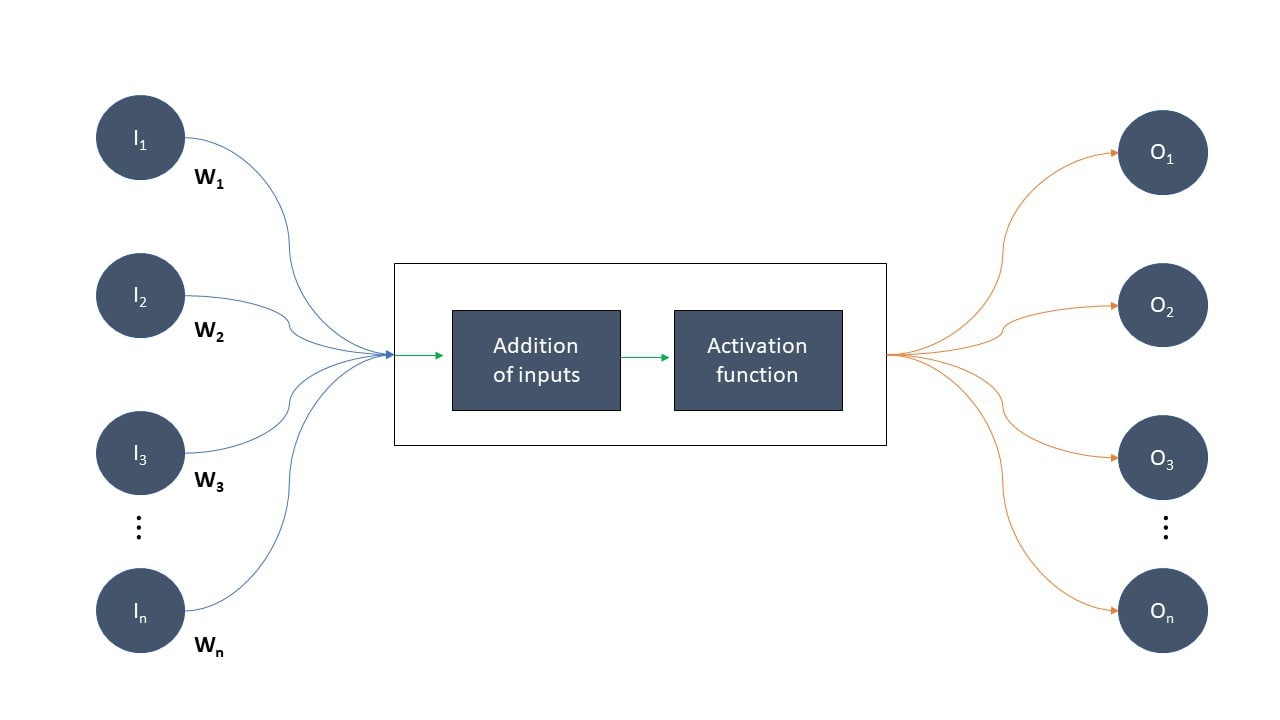
The pharma market trends impact logistics with a shift to smaller, higher-value shipments and new temperature requirements.

This blog post explores the role of remanufacturing and outlines how it can be successfully integrated into Product Lifecycle Management.

No-Code technologies allow businesses to adapt their transport management strategies swiftly and flexibly without complex programming.

In this blog post, you will learn the important difference between CX software solutions and customer experience as a business orientation.
