
Navigating Pharma Logistics: Trends, Challenges, and Solutions for 2025
The pharma market trends impact logistics with a shift to smaller, higher-value shipments and new temperature requirements.


For decades, data platform architectures have been following monolithic patterns like data warehouses, complex data lakes or data lake houses. All of that is usually managed by a team of specialists taking care of the data landscape and its pipelines. This team of data specialists has to align with data owners, business specialists and requirement requesters to provide specific data sets. The members of this team have a very specific profile: while understanding the data and talking with the business specialists, they also need to be able to implement the data pipelines and structures in the specific system. Exactly this is the bottleneck in today’s data organization. Also, the centralization of data in the data warehousing layer often results in complex data structures which become increasingly difficult to maintain and govern the longer this layer exists.
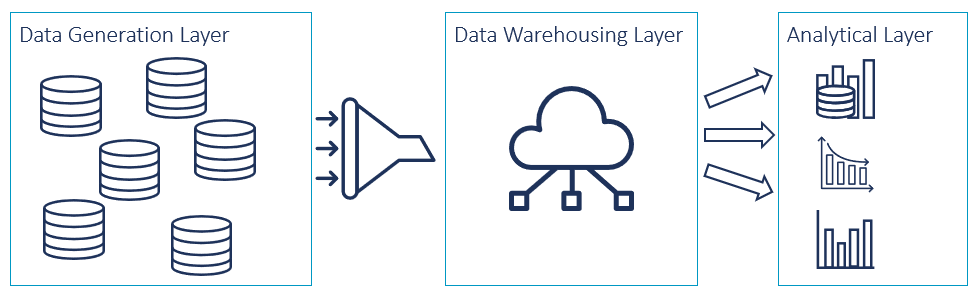
The concept of data mesh breaks with the existing patterns in order to prevent unmanaged, neglected and cluttered data lakes, so-called data swamps, from turning malicious. Therefore, the monolithic centralized data architectures are re-organized following an approach based on domain-driven design. To achieve this, the ownership of the data is decentralized and assigned to domains whose teams are most intimately familiar with the data and are in control of it from the source. Other parties in the company can consume the ready-to-use data provided to them by the responsible domain as data products. It is the task of the domains’ cross-functional teams to define the data products from a business perspective, implement data pipelines and provide scalable endpoints which are accessible via modular interfaces. This way, we move the functionality of the long-established pipelines between the data-generating operational planes, centralized databases, and the analytical layer into the responsibility of the domains, making the process more efficient.
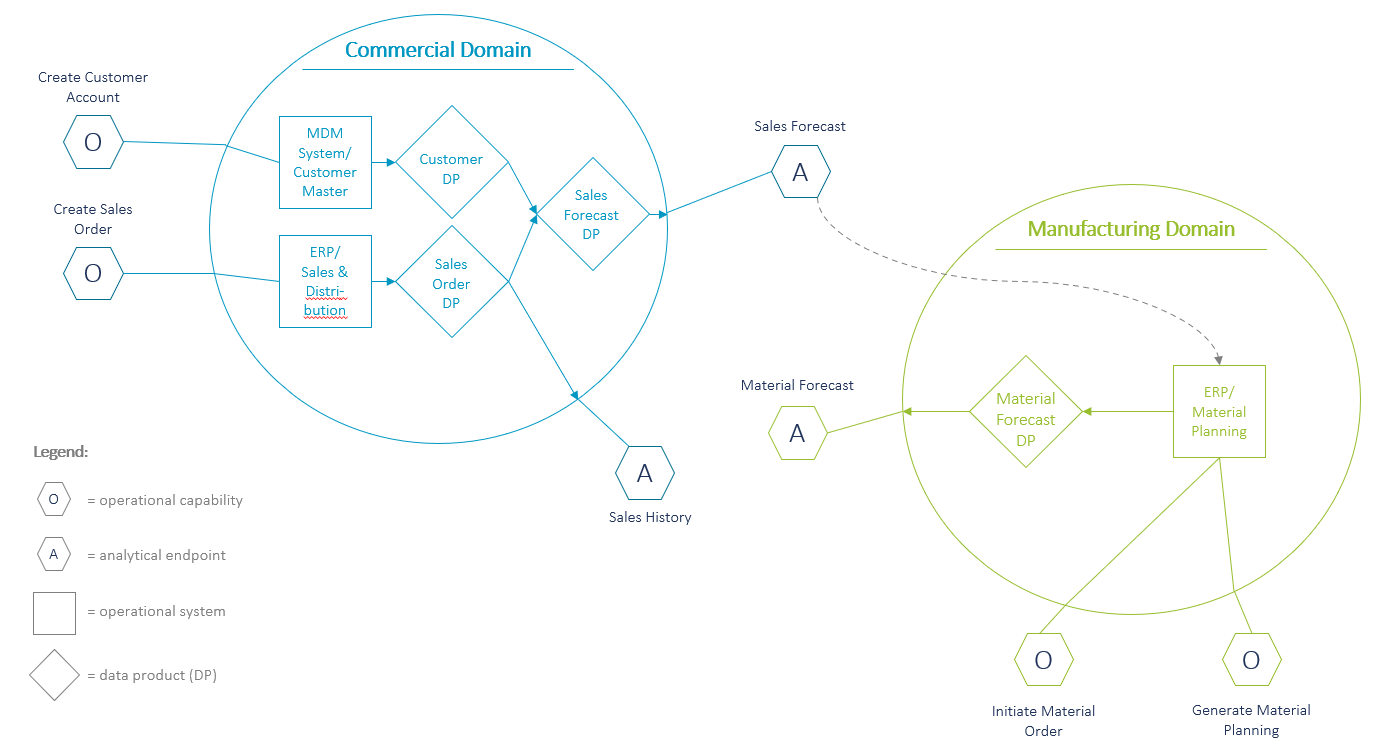
Figure 2 displays how a domain architecture could look like for a pharmaceutical company. For example, the commercial domain has so far been responsible for the operational “Sales Distribution” functionality in the ERP system and thus has already been familiar with the sales order data prior to the data mesh implementation. In the context of the data mesh, the domain’s responsibility is extended to provide its data to other consumers throughout the company as data products, e.g., the “Sales Order Data Product”. There will be one or several teams being responsible to define the data products and deliver them through defined analytical data endpoints (labelled “A” in fig. 2) at a defined service level and quality. On the other hand, for example the manufacturing domain might use the “Sales Forecast Data Product” to feed its “Material Planning” in the ERP system and generate a material forecast which will then be exposed as the “Material Forecast Data Product”.
Data products break down the data architecture into independently deployable subsets which comprise the following aspects:
Data-as-a-product can generate additional value and facilitate the usage of its users like data analysts and data scientists only if it is discoverable, addressable, trustworthy, self-describing, interoperable and secure. Therefore, we need a self-serve data platform that enables product owners to establish a high level of interoperability and interconnectivity between data products. At the same time, this centralized platform hides the complexity of the underlying infrastructure from the domain teams. This is essential as the technology stacks of big data and operational platforms have been diverging. Finally, it is crucial to establish a new federated approach on how to jointly agree on global rules and policies, in order to ensure that distributed data remain secure, governed and interoperable whilst attempting to preserve the domain’s autonomy in local decision-making.
The pharma market trends impact logistics with a shift to smaller, higher-value shipments and new temperature requirements.

This blog post explores the role of remanufacturing and outlines how it can be successfully integrated into Product Lifecycle Management.

No-Code technologies allow businesses to adapt their transport management strategies swiftly and flexibly without complex programming.

In this blog post, you will learn the important difference between CX software solutions and customer experience as a business orientation.
