
The Power of Automation in Data Migration
Automation is a practical solution to speed up and optimize the entire data migration process


A data catalog is the organized inventory of distributed datasets of an enterprise, including the collection of metadata and various capabilities useful for different teams. It enables professionals with diverse roles to manage, access, and process the data in order to extract the value of it that they need. Furthermore, it bridges the gap between data sources and data users. By enabling the availability of data for everyone throughout the company, data catalogs create the foundation for extracting value from the data through analytics, data science and machine learning.
In this blog post, we will have a closer look at the main capabilities and features of most available data catalog solutions:
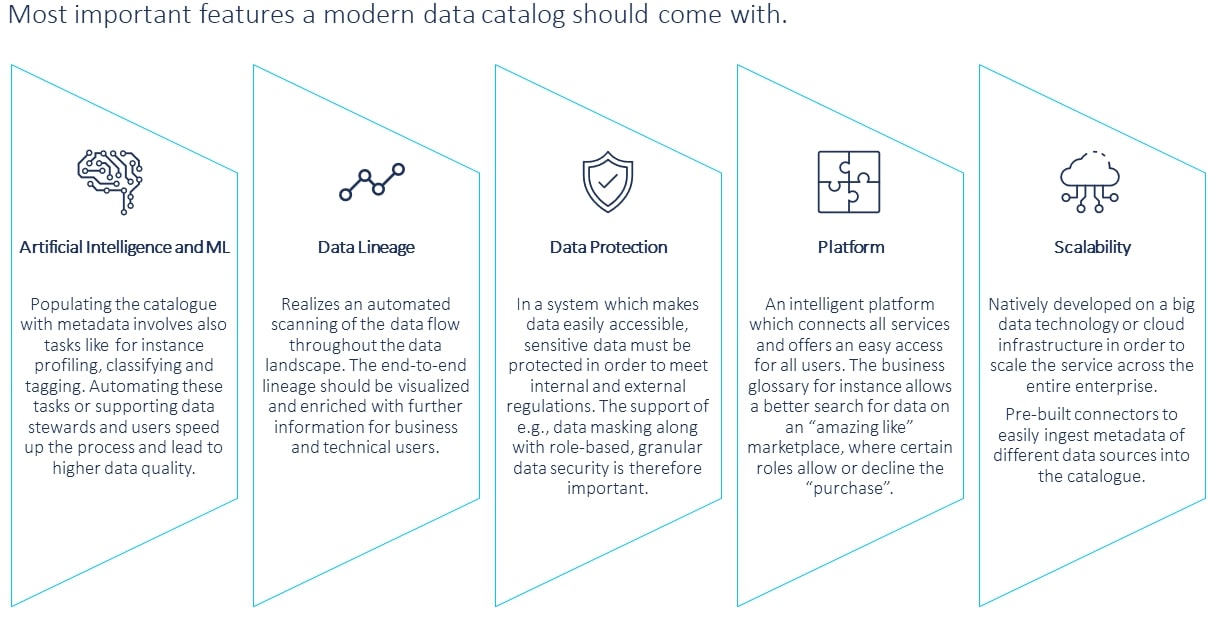
Some data catalog products also combine these functionalities with machine learning and artificial intelligence in order to automate and enhance aspects of data governance. Possible scenarios are, for example, the use of behavioral analysis or the automation of tasks like profiling and classifying. As a result, these techniques help to increase data quality, accuracy, and efficiency to enable companies to cope with the increasing amount of data to be managed.
Data catalogs can also help to ensure the protection of sensitive data by supporting role-based access, anonymizing data before cataloging as well as implementing data policies. Lastly, the data catalog solutions on the market currently usually offer pre-built connectors to integrate data sources of the most commonly used types with minimum configuration effort. A modern catalog connects all components in an intelligent platform and is developed on big data or cloud infrastructure to allow scalability. The most important features of a modern data catalog are summarized in figure 1.
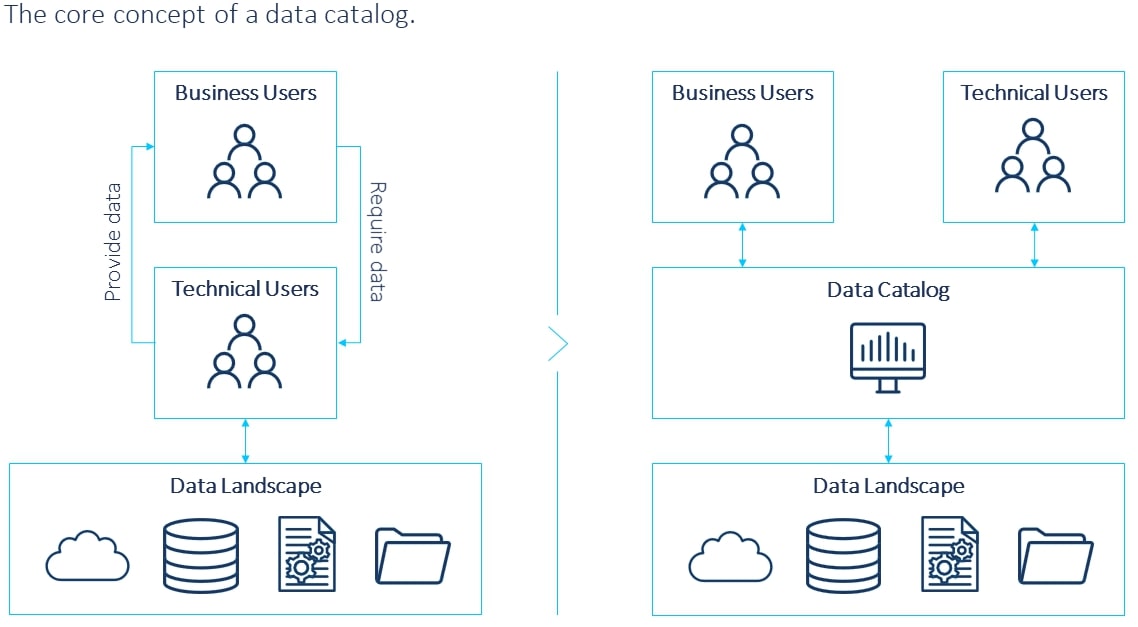
In a classical approach, data engineers and data scientists are usually the ones handling the data. However, they mostly lack the business perspective and the context of the data. In order to accurately analyze and unlock the real potential of data, the business perspective is a must. Therefore, the accessibility for all teams that can derive value from the data must be enabled by making the data visible and understandable. With this, we are talking about “data democratization”. Data catalogs are great enablers at this point because of all the features they provide, like the metadata, glossary, or functionalities to collaborate across teams. The core concept of a data catalog is depicted in figure 2.
As mentioned before, the core features of data catalogs are means to provide attributes of data products that are a prerequisite of data mesh. This new architectural approach has been a hot topic as it applies organizational measures to overcome the bottlenecks of traditional data architectures like data warehouse or data lakes. For a more detailed introduction, please visit our blog post on data mesh. It moves away from centralized data management to a decentralized domain-based approach, especially for analytics data assets. Cross-functional teams, which are most familiar with the data, are made responsible to provide data as a product to other parties throughout the enterprise.
By doing so, data mesh intends to overcome the necessity of a central team of technical experts that has to become active for the provision of data to consumers. It rather relies on a central self-serve platform making data products findable, accessible, interoperable, and reusable, also known as the FAIR principle. On the one hand, the platform enables data product owners to create data products with a high level of interoperability and inter-connectivity. On the other hand, it allows consumers to serve themselves with the data they need and understand the data. With a data catalog as a crucial part of the infrastructure for a data mesh, it becomes a key enabler for internal and external data sharing.
In the end, a data catalog always needs to be a customer-specific tool selection or combination of tools because the solutions on the market have all their own strengths and focuses. Thus, there is no comprehensive tool which fits all customer needs and the reason why it is necessary to select the right tool based on the customer specific requirements. For more information, please get in touch with us.
The authors would like to thank Yosr Cheikh and Gregor Titze, consultants for data and analytics, for their contributions to this article.
Automation is a practical solution to speed up and optimize the entire data migration process

Discover how you can streamline your financial master data management and reengineer financial processes with SAP MDG Finance.

Whilst it seems straightforward to carry out either a blood transfusion or a data migration, the actuality proves far more complex.

In this blog article, Camelot introduces you to the main principals of Demand-Driven Supply Chain Management.
