At CAMELOT, we provide flexible use cases that are based on projects in different industries. CADET is powered by Amazon Textract to convert the documents into text that is understood by the computer, using OCR. Here, we provide the summary of the largest projects with CADET.
Extraction of data using customer-defined templates
Does your company face the data extraction challenge of thousands of documents with similar structure that need to be manually reviewed? With structured data, you upload a form to our intuitive web application CADET. You only must define the places of the document where you expect to find different data fields. We achieved at least 92 percent accuracy in handwritten forms in our previous projects using the structured data extraction, thanks to the unique combination of Amazon Textract and our post-processing automated validation.
Material specifications for suppliers
If you are a large company that works with several hundreds or thousands of suppliers, this might be your use case. One of our customers faced the issue of receiving over 10,000 material specifications from different suppliers every month. Each supplier sends their own material specification format and measurements. Each specification might appear in any part of the document and not all the specifications are present in every document.
We input the text extracted by Amazon Textract into our own machine learning algorithm that can correctly identify material properties, their measurements, and units (if applied) with an accuracy of 89 percent (+/-5 percent). This translates in roughly 27 out of 30 correct data entries extracted by document. The user interface allows users later to validate the data extraction from CADET. To facilitate this task, CADET outputs a probability of every data entry being correct.
Batch report digitization in the biotech industry
Improving processes in the biotechnological industry needs the analysis of vast amounts of data. Currently, most biotech companies include the data reports manually into Excel sheets to then analyze them. This generates an enormous overhead that prevents them from a data analysis that provides reals value. Thanks to CAMELOT’s CADET, biotechnical companies are now able to automate the data extraction, obtaining the data in the correct forms and schemas with an extraction accuracy above 92 percent, including handwritten forms.
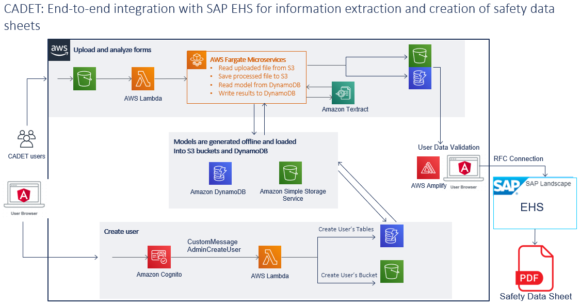
End-2-End Integration with SAP ERP Systems for Safety Data Sheets
Safety is key. Safety data sheets are mandatory in most chemical industry settings and closely regulated by several compliance standards. Furthermore, these data sheets must be generated in the language of the country of destination. To support with data extraction and document creation for safety data sheets, we replicated this process with CADET for two customers in the chemical industry.
Next to data extraction, our solution covers the entire end-to-end process of data digitization. Thanks to CAMELOT’s experience with SAP, we can integrate our data extraction solutions with different ERP systems.
In the case of safety data sheets, the SAP relevant system is the “SAP Environment, Health, and Safety Management” (EHS). The EHS system contains the standard regulations to generate safety data sheets out of the inputs to the system. We use the data extracted with CADET as an input to generate the required safety data sheets using the EHS system. We achieve this thanks to an RFC connection to the EHS system and the required ABAP code to generate the safety data sheet.
This solution is under current development. Currently we can successfully extract information from the sections 1, 2, 8, 9, and 14 of the safety data sheets and successfully generate safety data sheets. We plan to extend this to the entire document and make it available as SaaS in AWS by the end of 2022.