
Navigating Pharma Logistics: Trends, Challenges, and Solutions for 2025
The pharma market trends impact logistics with a shift to smaller, higher-value shipments and new temperature requirements.


Association rule mining is a simple, yet powerful technique utilized for discovering hidden patterns between attributes in large datasets. Association rule mining methods are commonly used for market basket analyses. For the customers’ shopping behavior, the algorithm identifies products that are commonly bought together and translates these frequent item sets to rules. This information can be utilized for the placement of products next to each other, if they are often bought together. Another example is the list of products suggested to online shoppers when they are viewing a product. There are many more steps in a company’s data management processes where rule mining will add value, as in exploring the data structure, supporting forms fields population with predictions and rule compliance check across multiple data sources.
The rule mining algorithm derives association rules from any relational data. The mined rules represent the probability of occurrence of a specific value given the known presence of other values. The derived set of rules are in the form of IF-THEN (also named: Antecedent – Consequent) statements. Each of the derived rules can be quantified by two essential metrics:

The extracted rules will have the following structure: A ⇒ B (Support: 50%, Confidence: 90%)
This rule informs us based on the given data: Given the value A is found in a data entry, there is a 90% chance of also finding B in the same data entry, with this item set occurring in 50% of all data entries in the entire data set.
To understand the concept of association rule mining, we will use a classical market basket analysis example. We have a shop selling six items: wine, pears, hamburger, cheese, ice cream and cherries. We have five transactions representing the shopping basket of five different customers. The first customer bought [hamburger, cheese] the second customer bought [hamburger, cherries, wine, ice cream] and so on. By using the formulas given above we extract a set of exemplary rules.
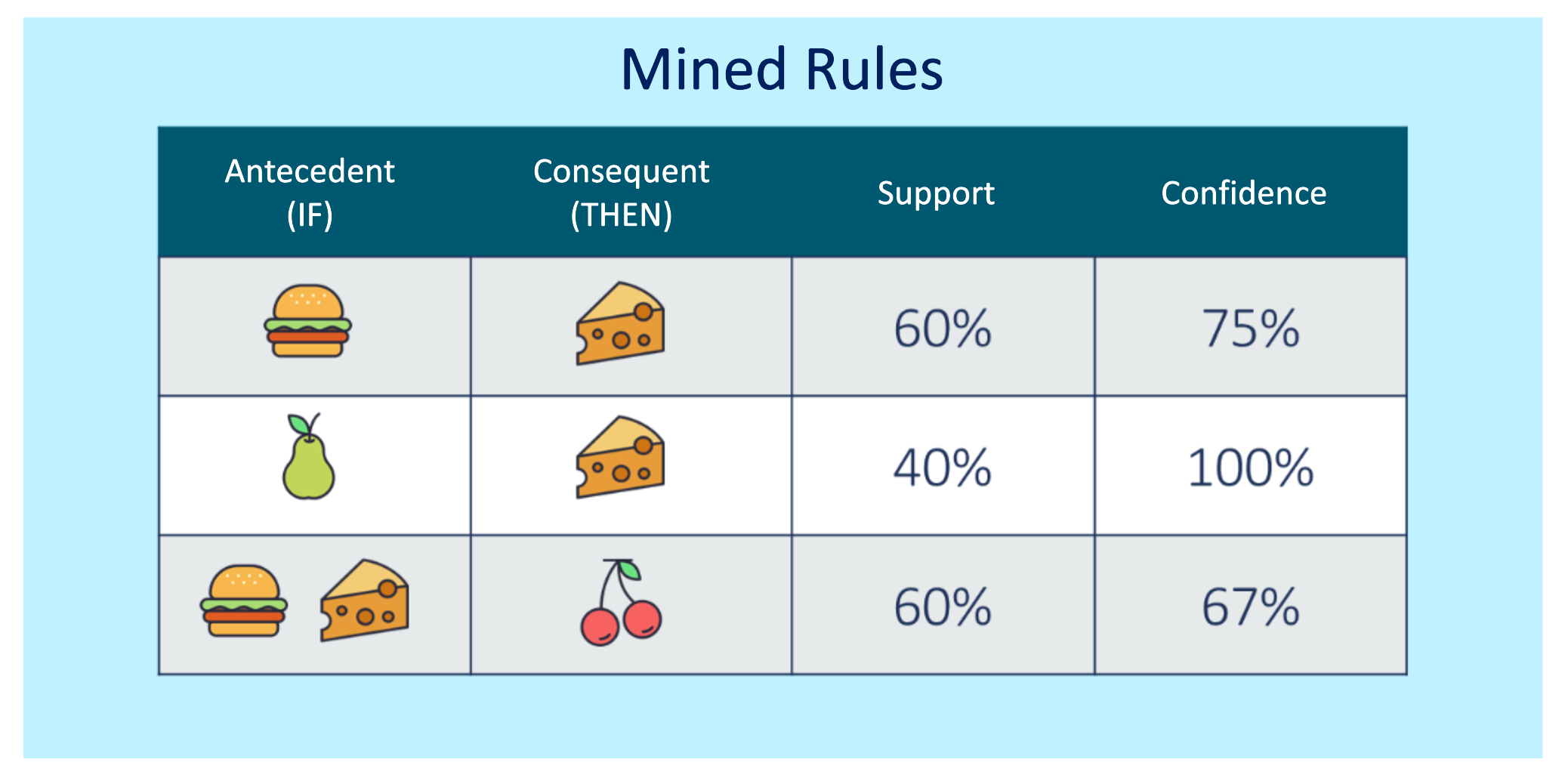
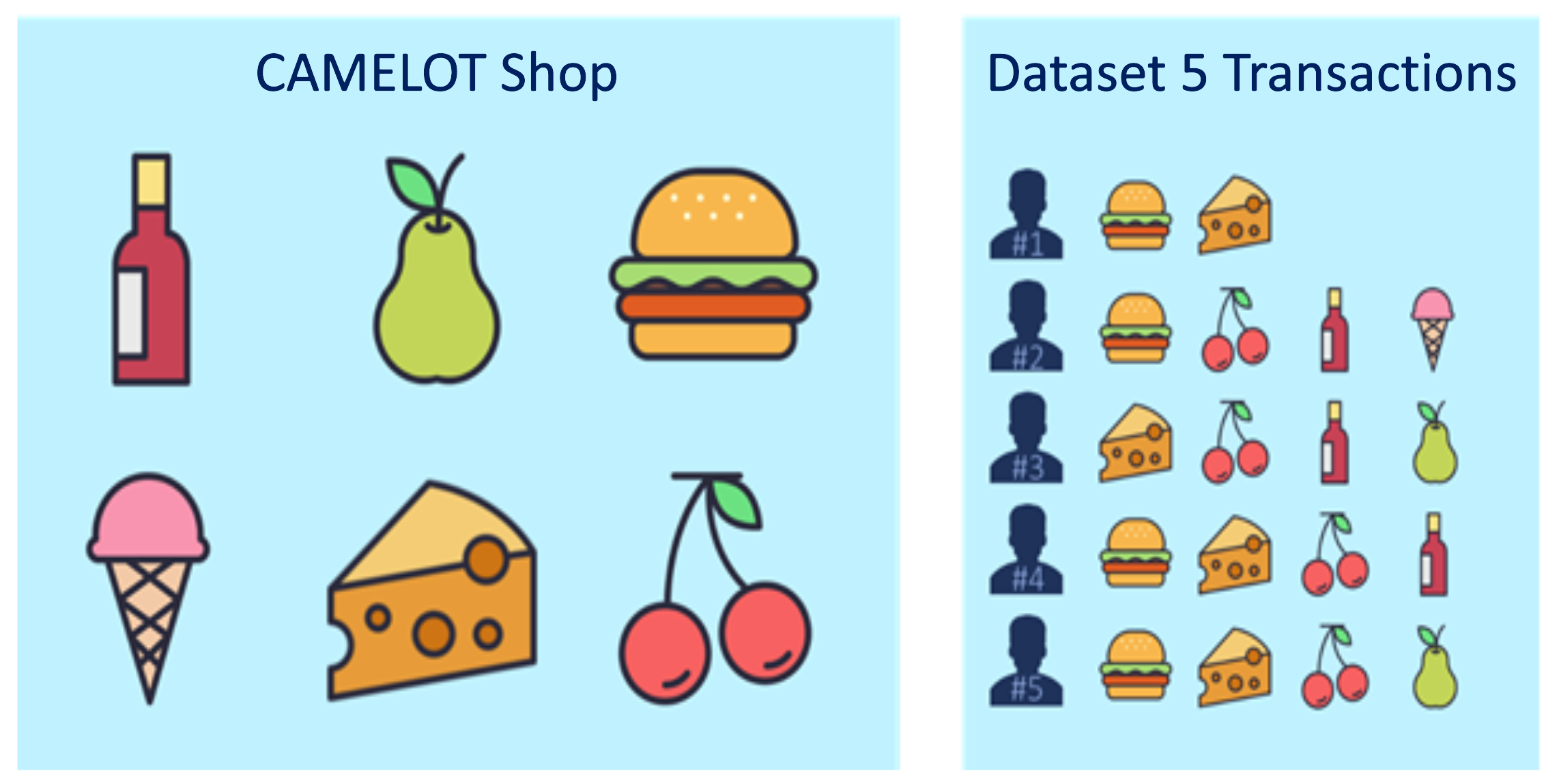
Figure 2 & 3: Market Basket Analysis Example with Mined RulesAs we observe in the table above, the first rule states that 75% of the customers who purchased a hamburger also bought cheese, with this relation occurring in 60% of the dataset. The second rule states that 100% of the customers who bought a pear also bought cheese, with the rule occurring as well in 40% of the data. Finally, the third rule is more complex, stating that 67% of the customers who bought a hamburger and cheese also bought cherries, while occurring in 60% of the data.
This simple example gives us an insight into the process of association rule mining. In practice, such algorithms are highly optimized and capable of computing large data sets for an immense number of rules in a few seconds. In practice, a small cluster of 10 computers can mine a million rules in less than a minute.
The pharma market trends impact logistics with a shift to smaller, higher-value shipments and new temperature requirements.

This blog post explores the role of remanufacturing and outlines how it can be successfully integrated into Product Lifecycle Management.

No-Code technologies allow businesses to adapt their transport management strategies swiftly and flexibly without complex programming.

In this blog post, you will learn the important difference between CX software solutions and customer experience as a business orientation.
